
Internet Basics -
Understanding URLs

Internet Basics
Understanding URLs

search
menu
/en/internetbasics/using-search-engines/content/
Every time you click a link on a website or type a web address into your browser, it’s a URL. URL stands for Uniform Resource Locator. Think of it like a street address, with each portion of the URL as different parts of the address, and each giving you different information. Let’s examine each component of a URL and what we can learn from it.
Watch the video below to learn the different parts of a URL.
Every URL begins with the scheme. This tells your browser what type of address it is so the browser connects to it correctly. There are many types of schemes, but for typical web browsing you will mostly see http and https. Your browser usually won’t show the scheme in the address bar, and usually you don’t need to type the scheme when typing a web address; instead, you can just begin with the domain name. The scheme is still always part of the URL; it just isn’t being displayed.

The domain name is the most prominent part of a web address. Typically, different pages on the same site will continue to use the same domain name. For example, all pages on this site share the GCFLearnFree.org domain name.

Each segment of the domain name separated by a period is called a domain. The domain on the right is called a top-level domain, with the domain to the left of it called the second-level domain, then third-level domain, and so on.
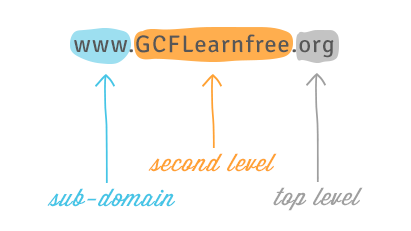
You can often learn something about the site from the domains. One of the domains usually identifies the organization, while the top-level domain may give you more general information on what kind of site it is. For example, in the domain name nc.gov, the .gov domain means it is a government website in the United States, the nc domain identifies it as the website of North Carolina.
In most URLs, the www domain can be omitted. Google.com and www.google.com lead to the same page. However, other subdomains cannot be omitted. For example, all pages under news.google.com require the news subdomain in the URL.
The file path—often just called the path—tells your browser to load a specific page. If you don’t specify a path and only enter a domain name, your browser is still loading a specific page; it’s just loading a default page, which usually will help you navigate to other pages.

URLs that end with the domain name without a file path usually will load a homepage or an index page that's designed to help you navigate to specific pages on the site. Often, if you can’t remember the file path for a specific page, you can go to the homepage and search for it.
Some URLs include a string of characters after the path—beginning with a question mark—called the parameter string. You have probably noticed this part of a URL appear in your address bar after performing a search on Google or YouTube. The parameter string can be clear or confusing to a human user, but it is critical information for the server.

Also appearing after the path, the anchor tells your browser to scroll to or load a specific part of the page. Usually the anchor begins with a hashtag and is used to direct your browser to a specific part of a very long page, much like a bookmark. Different anchors don’t load different pages; they simply tell the browser to display different parts of the page.

When combined, these elements make up a URL, although not all URLs will have all five parts.

Using what we learned in this tutorial, we can tell from the domain name of this URL that it’s on Wikipedia, from the parameters that the page is probably about burritos, and from the anchor that we’ll be looking at the section on burritos for breakfast.
Keep in mind that these are the most common components of a URL. There are many other parts, but these are the five you will see most often and that can usually give you the most information.
/en/internetbasics/how-to-set-up-a-wifi-network/content/